How to use Camelot in Python to Extract data from PDF documents
Introduction
PDF or Portable Document File format is one of the most common file formats in today’s time. It is widely used across every industry such as in government offices, healthcare, and even in personal work. As a result, there is a large unstructured data that exists in PDF format and extracting this data to generate meaningful insights is a common work among data scientists.
There are several Python libraries dedicated to working with PDF documents such as PYPDF2 etc. In this tutorial, I will be using Camelot.
Why Camelot?
- You are in control: Unlike other libraries and tools which either give a nice output or fail miserably (with no in-between), Camelot gives you the power to tweak table extraction. (This is important since everything in the real world, including PDF table extraction, is fuzzy.)
- Bad tables can be discarded based on metrics like accuracy and whitespace, without ever having to manually look at each table.
- Each table is a pandas DataFrame, which seamlessly integrates into ETL and data analysis workflows.
- Export to multiple formats, including JSON, Excel, HTML, and Sqlite.
Let’s Begin
Before installing Camelot libraries we have to install ghost script , once we install the ghost script lets installcamelot-py.
Run below commands :
pip install "camelot-py[cv]"Once you have installed camelot-py library we are all set to go. We are trying to extract a state-wise GST revenue table from this pdf doc.

Pdf table
import camelotIf you have camelot, Python will not print an error message, and if not, you will see an ImportError.
# Syntax of the camelot.read_pdf function
camelot.read_pdf(
filepath,
pages='1',
password=None,
flavor='lattice',
suppress_stdout=False,
layout_kwargs={},
**kwargs,
)If you have to extract a table from different pages you have to give the page number.
tables2=camelot.read_pdf('gst-revenue-collection-march2020.pdf', flavor='stream', pages='0-3')
tables2
This will give you a total Table list that is there in a pdf doc. we can select a table passing the index.
tables2[2] # 2 is the index
tables2[2].parsing_report
The above code will give you the details such as accuracy and page no. Note that there are 2 pages.
The following code will extract the table from the pdf document.
df2=tables2[2].df
df2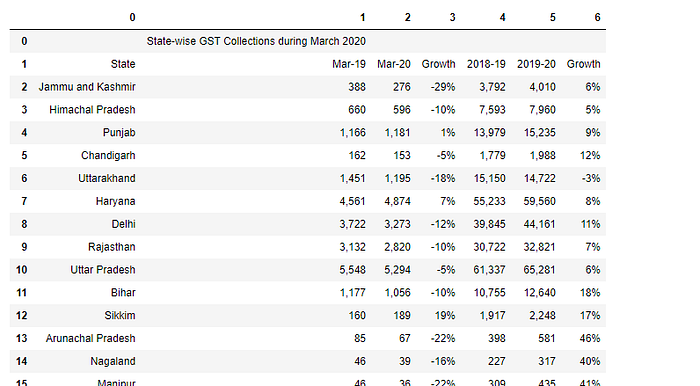
In this case, because the table is split into two different pages. So we can do a workaround.
tables2[3]
tables2[3].parsing_report
Here you can notice, we extract the table from page no 3.
df3=tables2[3].df
df3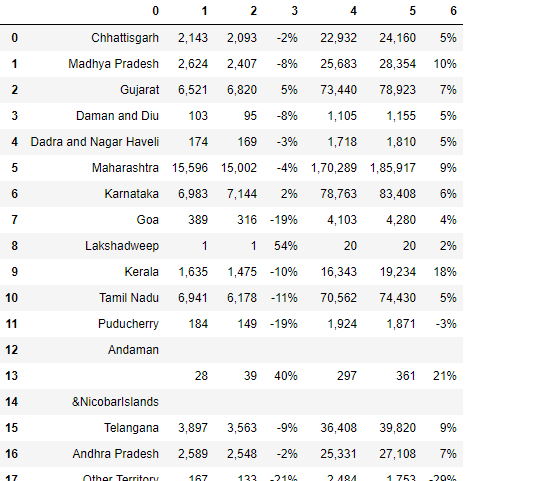
The following is the code to append df2 and df3.
df4=df2.append(df3)
df4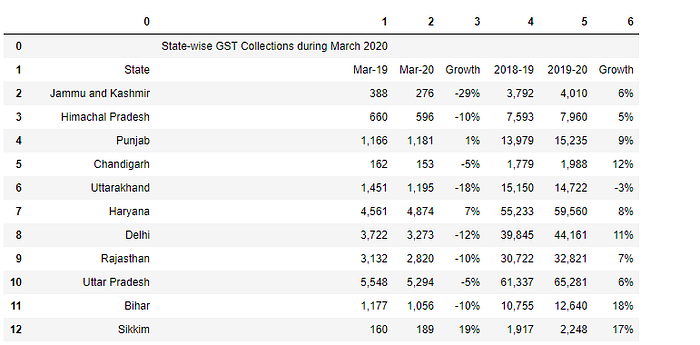
df5=df4[1:]
df5.head()
new_header = df5.iloc[0]df5 = df5[1:]df5.columns = new_header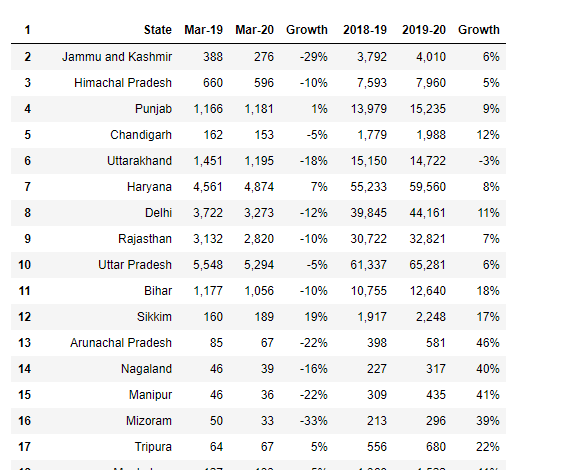
Here you go, we have extracted a table from pdf, now we can export this data in any format to the local system.
Conclusion
Extracting tabular data from pdf with help of camelot library is really easy. Moreover, we know there is a huge amount of unstructured data in pdf formats and after extracting the tables we can do lots of analysis and visualization based on your business need.
I hope this article will help you and save a good amount of time. Let me know if you have any suggestions.
